Paper:
Background
연속적인 multitasking은 switch cost를 만든다. switch cost는 하나의 작업에서 다른 하나의 작업으로 전환할 때 발생하는 비용이다. switch cost는 곧 인간에게 stress, furstration 그리고 task에 대한 error rate을 높인다. 다행히도, multitasking에 대한 연구들은 다음과 같은 사실을 밝혀냈다: switch cost가 tasks의 경계에서는 낮다는 것. 이제 문제는 task switch에 사용할 적절한 tasks boundaries를 찾아야 한다는 것이다. 이 문제를 해결하기 위해 AMS (Attention Management System)라는 것이 고안되어 왔다.
Problem with previous model
기존의 AMS는 thoeries와 concepts에 기반했다. 그래서 특별한 기법으로 주어진 문제 상황에서 tasks boundaries를 찾아 왔다. 문제는 theory 기반이든 data 기반이든 두 모델은 인간이 data를 label해야 하는 제약 때문에 개발하기 어렵거나 inflexible하며 실제적으로 불가능할 수도 있다.
따라서, 이 논문에서는 AMS에 RL(Reinforcement Learning)과 CR(Computational Rationality)를 적용한 AMS를 제안한다. 기존에는 거의 존재하지 않았던 sophisticated real-time AMS이다.
*Computational Rationality: 여기에서는 RL agent가 사람이 하는 것과 비슷한 action policy를 얻도록 train시에 human constraints를 반영한다는 의미. 구체적으로, AMS 모델에 인간의 시각 정보 처리 과정, 반응 속도나 기억의 한계를 반영한다는 의미다. 인간과 인공지능 사이에 gap을 완화할 수 있도록 적용된 개념이다.
Basic experiment concept
RL-기반 AMS는 하나의 fast-paced dual-task로 실험이 진행되었다. 한 번에 하나의 platform만 활성화해서 균형을 잡을 수 있는 게임이다. 이 게임으로 AMS agent와 balancing agent도 train하고, 4가지 조건으로 사용자들의 performance를 평가한다: cognitive model, unconstrianed, notification, unsupervisor.

cognitive model은 사람이 coginitive constraints를 고려한 AMS와 함께 task를 수행한다. unconstrained는 사람이 어떤 제약도 없는 상태로 훈련한 AMS와 함께 task를 수행한다. notification은 cognitive model로 task를 수행하지만 task-switch는사람에게 알려주기만 하고 결정은 사람이 한다. unsupervisior는 이 실험에서 baseline이며 인간 스스로 task를 수행한다. 앞의 두 모델은 task-switch를 자동으로 해준다.
Methodolgy
두 agents가 있다. 하나는 AMS agent, 나머지 하나는 balancing agent. AMS는 balancing agent를 인간처럼 여기고 switch하거나 stay하면서 action policy를 학습한다. 학습이 완료되면, 인간이 multitasking하는 과정에서 mode에 따라 task-switch를 돕는다.

Methodolgy (RL-problem definition)
AMS agent와 balancing agent (unconstrained)는 각 platform의 true state에 접근할 수 있다. 따라서, 이 RL-problem은 하나의 MDP(Markov Decision Process) 기반에 기반하여 정의될 수 있다. 추가적으로 그 agent들이 가지는 state는 8-size vector가 된다. position of ball(3), angle of surface(2) and velocity(3). 당연히 AMS는 두 platform에서의 정보를 가지므로 vector 두 개를 가진다.

그러나 balancing agent (cognitive mode)는 위처럼 정의될 수 없다. 인간의 기억력은 불완전하기 때문에, inactive platform에서의 state에 대한 불확실성을 반영해야 한다. (시각 정보에 대한 불확실성도 있기 때문에, active platform에서도 약하게 반영한다) state를 확실하게 알지 못하기 때문에 belief state(probablistic)라고 표현하고 이 RL-problem은 하나의 POMDP (Partially Observable MDP)에 기반하여 정의될 수 있다.

그러나 한 가지 문제가 있다. 이 게임은 continuous state space라는 점이다. belief state는 density function으로 표현될 수 있지만 계산량을 너무 많기 때문에 discretization(이산화)를 적용하였다. 따라서 b(s)는 각 postion에 대한 공이 있을 확률값을 가진다.
먼저 p(s'|a,s)에 대해서 살펴보자. platform이 active인 경우 추정되는 velocity가 실제 velocity와 같지만, inactive인 경우, 존재할 수 있는 추정되는 velocity를 sampling해야 한다. 여기서 추정된 velocity를 이용해서 p(sampling된 velocity)를 구해야 한다. 아래 그림과 같이 sampling이 진행된다.

두 deviation(𝜎) 모두 고정된 값을 가진다. 그 고정된 값으로 초기화된다는 표현이 더 정확하다. sampling 진행 시에 첫 step에서는 추정되는 속도를 기반으로 하는 noraml distribution에서 vector를 추출한다. 그 뒤에는 평균값을 다시 그 vector를 평균으로 하는 또 다른 normal distribution에서 추출한다. 이 과정을 반복한다. 모든 반복마다 𝜎_mean 값이 0에 가까워지므로, 특정 값에 수렴한다. 따라서, n(정해지지 않음)개 만큼의 sampling이 완료될 수 있게 한다.
sampling된 velocity를 사용해 position i에서의 후보 position j를 얻는다. 각 position(j)이 가진 probability를 사용해서 position(i)를 갱신한다.

추가로, 여기서 구해진 postion들의 확률에 Observability를 곱한 후 갱신한다. active platform에서는 true state만 높은 값을 가지고, 나머지는 균일하게 낮은 확률을 가진다. inactive platform에서는 보정 없이 불확실한 상태를 계속 유지한다.

예를 들어 active 되어있다가 바로 inactive로 바뀐 platform에 대해 생각해보자. 위의 과정을 미루어 보았을 때, 공이 있던 position은 belief state의 probability가 높을 것이고, 나머지는 그것을 기점으로 멀어질수록 점점 낮은 확률로 구성될 것이라고 추측할 수 있다. 이 상태로 시간이 지나면, random 추출한 값으로 인한 갱신으로 인해 분포의 정확성은 계속 떨어질 것이다. 이와 같은 절차를 통해, CR이 잘 적용된 model을 구성할 수 있다.
Methodolgy (reward)
AMS agent의 reward function은 아래 그림과 같다. \Delta t_{s}는 작업 전환 시간 간격이다. 시간 간격이 짧을 수록 reward는 급격하게 0에 가까운 값이 된다. 양쪽의 공이 둘다 안정적인 경우에, 불필요한 swtiching을 방지하기 위한 것이다.

balancing agent의 reward function은 아래 그림과 같다. radius는 platform의 반지름이고, D_{t}는 공과 platform의 중심과의 거리이다. 멀어질수록 reward는 감소한다.

Experiment and Result
실험 결과는 가설을 만족한다. unconstrained model보다 CR을 적용한 cognitive model이 더 우수한 performance를 보여준다. AMS가 인간을 잘 모델링한 agent를 통한 훈련이 성공적이었다는 것을 의미한다.

가장 왼쪽이 cognitive model과 함께 task를 수행한 user performance를 나타낸다. 아래 그림을 보면 가장 높은 performance를 보여준다는 것을 알 수 있다.

아래 그림은 performance가 높았던 두 조건만 비교한 자료다. AMS의 도움을 받을 때가 switch하기 까지 소모한 시간이 인간 스스로 결정할 때보다 적었다. 인간이 더 주의깊게, 심지어 performance에 부정적인 영향을 주더라도 하나의 task를 안정적으로 마무리하려는 경향이 있다는 것을 보여준다. 이것은 ball distance 비교 자료에서도 확인할 수 있다.

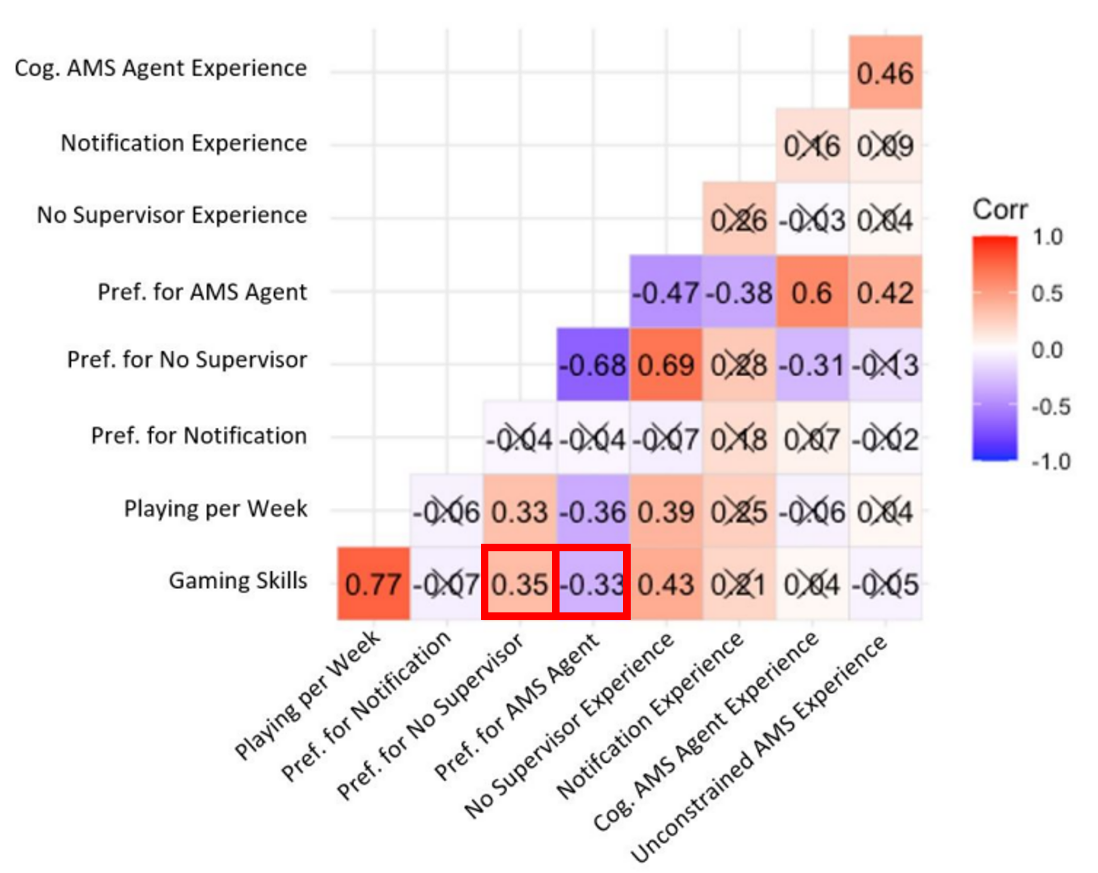
아래 그림은 user의 performance가 높을 때, AMS의 선호도가 떨어지는 (약한)상관관계가 있음을 보여준다.
Discussion
cognitive model에서의 measurement를 볼 때, performance가 개선된 것 뿐만 아니라 user가 주관적으로 느끼는 workload(mental and physical)가 낮아졌고, user의 선호도도 높았다. 하지만, notification이 기대했던 것만큼 performance 개선에 도움을 주지 못했다. 인간의 판단으로 인한 workload가 추가적으로 발생하는 것이 원인이다.
large labeled-data가 필요없다는 점에서 발전된 모델이라고 할 수 있다.
Pearson Correlatoin Matrix를 보았을 때, user의 실력에 따라 선호도가 나뉜다는 점에서, user difference를 충분히 고려하지 못했다는 것을 보여준다. 그러므로 human-constraints도 충분히 넓은 범위를 다루지 못한다는 것을 알 수 있다.
마지막으로, 여기에서의 결과는 task-dependent하기 때문에 섣불리 모든 경우에도 이 결과와 같다고 판단할 수는 없다.
conclusion
기존에는 sophisticated AMS 거의 존재하지 않았다. RL과 CR을 적용해서 그 AMS를 develop했다. 또한 unconstrained model도 추가해서 비교함으로써, CR이 이 연구에서 key concept임을 보여주었다.
RL과 CR이 적용된 AMS가 실제로 인간의 performance를 개선했고, 더 sophisticated AMS에 앞의 두 개념이 활용될 수 있다는 것을 보여준다.